A demo focusing on the storage, preprocessing, and NLP required to perform short text modeling on Twitter data in Python. Per usual feel free to skip the personal motivation and direct yourself to the next section if my life is not interesting.

Motivation
About 2 years ago as I write this I flew from Atlanta to San Frencisco then rented a car and hauled up to Santa Rosa for the interview that would prompt my big move. As I drove over the beautiful Golden Gate bridge, wound through the redwoods, and started cresting into vineyard hills, the scenery shifted to a much more barren landscape. If you’re from California it isn’t hard to remember the horrible fires of 2017 in Santa Rosa. Neighborhoods were leveled. Stone foundations lined many. Now I said if you’re a Californian you’ll remember this. The story reads much differently from 2,000+ miles away in the humid Georgia air. My own naivity prompted me to wonder how the discussion shifts around large events like these both over time and over distance. How has the discussion changed and progressed since 2017?
Twitter is a pretty perfect platform for this kind of analysis for a few reasons:
1. Quantity of data
2. Diversity of opinion
3. Hashtags make topics easy to track
This post will focus on the methods and tools used to gather 2 years of tweets specific to wildfires and conduct topic modeling.
Gathering the Data
I had to make a few critical decisions pretty early on in this project to organize my data for analysis.
1. How do I pull the tweets from twitter?
This proved to be a more difficult problem than I orginially thought. Twitter does have an API, but you can only access tweets from the past week. Because I wanted to study wildfires over the course of 2 years this would not work. Luckily there are plenty of open sourcers out there, and it didn’t take me too long to find someone with a repository for collecting older tweets. The downside to this method is that the sparse location data available on the API is even less available through this repo.
Simply clone the repo, and queries are quite easy to run through the Exporter.py script. An example of one query I ran (command line) is below.
python Exporter.py --querysearch "wildfire" --since 2019-10-25
--until 2019-11-04 --maxtweets 10querysearch: allows you to specify a keyword
since: start date of search
until: end date of search
maxtweets: maximum number of tweets (if you simply want all of them then cut this out)
2. How do I store the data?
Any time you’re working with a large amount of data there’s the question of memory space and whether to pipeline into a database. I made 2 decisions here:
- I opened up an ec2 instance in AWS. I believe I picked the t2.xlarge instance, but anything large enough will do. If you run out of space there’s always the option to create an image of your environment and move to a new size.
- I decided to use a database to store the tweets. I used MongoDB in my AWS instance and pyMongo to interface with python.
To set up your Mongo database and import into the MongoDB database enter something like the following in the command line (after installing MongoDB of course):
mongod db.createUser({ user: 'brittany', pwd: xxxx,
roles: [{ role: 'readWrite', db: 'fires' }] });Next import the files:
mongoimport --username brittany --password xxxxx --db fires
--collection all --type tsv --file all_fires.tsv --headerlineFinally if you wish to do analysis in python you can import pyMongo as such:
from pyMongo import MongoClient
config = {
'host': 'XXXXXX',
'username': 'brittany',
'password': 'iheartdata',
'authSource': 'tweets'
db = client.tweetsPrecleaning the Tweets
Tweets come in pretty messy (as one would expect) with hashtags, links, emoji’s, etc. Luckily someone already made a preprocessor for some of these components. I combined this with a sprinkling of regex and checking for weirdness that the preprocessor missed. Here are a few lines I ran to preclean the tweets:
import preprocessor as p
import re
# convert to string
df['text'] = [str(x) for x in df['text']]
# lower case
df['text'] = [x.lower() for x in df['text']]
# Use preprocessor to clean text of hashtags, links, emojis, etc
df['text'] = [p.clean(x) for x in df['text']]
# remove links that the preprocessor missed
df['text'] = [x.split('http', 1)[0] for x in df['text']]
df['text'] = [x.split('pic.',1)[0] for x in df['text']]
# Removes text containing digits
df['text'] = [re.sub('\w*\d\w*', ' ', text) for text in df['text']]There are also duplicates in the dataset due to retweets. I removed and summed those in case there’s a useful signal in the number of retweets:
# Get rid of duplicate tweets, but keep track of number of retweets
retweets = [x for x in df.groupby('text')['retweets'].sum()]
df = df.drop_duplicates(subset = 'text')
df['retweets'] = retweetsStemming and Lemmatization
The central idea behind stemming and lemitization is to shorten words to their root for grouping (for instance wash, washed, washing, washer could all shorten to wash and for NLP that is probably enough). There are many packages attempting to do this, so I’ll save the full discussion for a dedicated post. For now there are many other people discussing it here and here. Essentially stemming clips words (like I did with the wash example) and lemmatization uses WordNet to assess the morphological representation of the word (for instance run and ran would fail stemming, but a lemmatizer could sort it out). I tried a few different packages for this and settled on a lemmatizer from Spacy, because it gave me the option to remove pronouns and other repeated parts of speach. A few lines I used for this are below:
from spacy.lang.en import English
from spacy.lang.en.stop_words import STOP_WORDS
import string
# Create a list of punctuation marks
punctuations = string.punctuation
# Create a list of stopwords
nlp = spacy.load('en')
stop_words = spacy.lang.en.stop_words.STOP_WORDS
# Load English parser
parser = English()
def spacy_tokenizer(sentence):
# Creating token object
mytokens = parser(sentence)
# Lemmatizing each token that is not a pronoun
mytokens = [ word.lemma_.strip() if word.lemma_ != "-PRON-" else word.lower_ for word in mytokens ]
# Removing stop words
mytokens = [ word for word in mytokens if word not in stop_words and word not in punctuations ]
# Remove mentions, hashtags, urls (the preprocessor throws a $ in front of these things)
mytokens = [word for word in mytokens if '$' not in word]
# Remove '...' which also showed up in a lot of the tweets after preprocessing for reasons unknown
mytokens = [word for word in mytokens if '…' not in word]
# return preprocessed list of tokens
return mytokens
df['clean_tweet'] = [' '.join(spacy_tokenizer(tweet)) for tweet in df['text']]Because I specifically searched for wildfire tweets I added a few more stop words to the list that spacy provides due to early results. I removed words that were too common to give a valuable signal. For example:
stop_words.add('wildfire')
stop_words.add('like')I also did my best to remove tweets which referred to things spreading “like wildfire” commonly associated with music tapes and the like. Below is an attempt:
for i,tweet in enumerate(df['clean_tweet']):
if 'michael' in tweet:
df = df.drop(i)
if 'youngadultfemalevocalistoftheyear' in tweet:
df = df.drop(i)Tokenize, Bigrams, Trigrams
Tokenizing is simply to split a sentance into a list of words. Some topic modeling packages will accept an entire string and tokenize internally while others prefer the tokenized version. You can also group words into “bigrams” and “trigrams” and use this group of 2 or 3 words as the token. This is something to play around with depending on the dataset. I found pretty good success with bigrams.
import nltk
df['bigrams'] = [[gram for gram in nltk.ngrams(tweet.split(), 2)] for tweet in df['clean_tweet']]Clustering and Topic Modeling Using GSDMM
Now we get to the good stuff! I already wrote up a post detailing how GSDMM works, so feel free to check it out here. The tldr is that GSDMM optimizes LDA for short text by clustering on the assumption that each document (tweet) is a topic. I detail out why LDA has shortcomings for short text in that post as well. I’ll focus on implementing a library for GSDMM here and looking at some early results.
The first step is going to be fitting the gsdmm to the tokenized terms. I created a function for this:
import mgp
def gsdmm(tokens, n_terms):
'''
This function takes a list of lists (tokens). It reteurns a fit mgp model.
tokens = tokenized documents
n_terms = length of vocabulary in tokens
--------------------
Inputs: list of lists, int
Outputs: model
'''
mgp = MovieGroupProcess(K=15, alpha=0.1, beta=0.1, n_iters=10)
y = mgp.fit(tokens, n_terms)
return mgpNext, you can visualize the topics using the below lines.
for i, topic in enumerate(mgp.cluster_word_distribution):
sorted_topics = sorted(topic.items(), key=operator.itemgetter(1),
reverse = True)
print('\n Topic: {}'.format(i))
print(sorted_topics[:20])In the case of wildfires I got results resembling the following:

There are a few other things you can do with the mgp package for GSDMM such as aggregating the number of documents in each cluster and predicting the most likely cluster of a new document.
How to interpret the topics?
Ok so now you’ve clustered and found your topics. What can we do with this? In my case I’m interested in the discussion shift from 2017 - 2019. One thing I am able to do is anlayze the quanitity of tweets per topic (normalized for the total in that year). This reveals a few interesting trends.
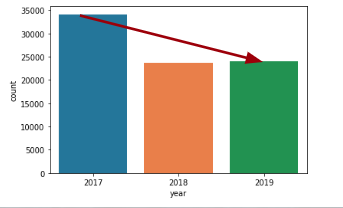
1. “Safety” tweets decline: I named this topic category for those tweets resembling number of acres burned, fatality of fires, personal accounts, etc.
2. “Climate” tweets increase: This topic resembles tweets related to air quality, power, and climate change.
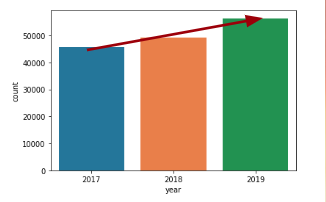
This can lead to the conclusion that perhaps the general public moved from a “shocked” stance the first few fires to a “responsive” stance in more recent years. At least qualitatively I believe the discussion has shifted a bit more toward the end of fiscal policy (at least in California) in recent years. In other words…fires have happened every year, so the response is no longer a shock but “what are we going to do to fix this?”
To sum up
I hope this tutorial was helpful. There are certainly many more NLP tools and clustering methods out there. I also performed a bit of sentiment analysis using out-of-the-box packages like Spacy and Vador. It was interesting to view sentiment by topic, for instance, to see how sentinment toward climate change has changed. In the future it may also be interesting to wrap location data into this. As I mentioned above, collecting historical tweets through the repo over the API revealed far less location data. Scraping from the API over time and preprocessing into a database may be a cleaner pipeline for future work.